Visual tracking technology is an important subject in the field of computer vision (artificial intelligence branch), and has important research significance. It has broad application prospects in many aspects such as military guidance, video surveillance, robot visual navigation, human-computer interaction, and medical diagnosis. With the continuous in-depth research of researchers, visual target tracking has made breakthroughs in the past ten years, making visual tracking algorithms not only limited to traditional machine learning methods, but also combined with the artificial intelligence boom in recent years— Methods such as deep learning (neural networks) and correlation filters. This paper mainly introduces the following points: what is visual target tracking (single target tracking), the basic structure (framework) of single target tracking, the challenges existing in target tracking, the classical methods and research trends of target tracking, etc.
01 Introduction to single target tracking task
Target tracking is an important problem in the field of computer vision, and is currently widely used in sports event broadcasting, security monitoring and drones, unmanned vehicles, robots and other fields. Below are some examples of applications.
![]()
Visual target (single target) tracking refers to the detection, extraction, identification and tracking of moving targets in the image sequence, and obtaining the motion parameters of the moving targets, such as position, speed, acceleration and motion trajectory, etc., so as to carry out the next step of processing and tracking. Analysis to achieve behavioral understanding of moving targets to complete higher-level detection tasks.
Its specific task is to predict the target state in subsequent frames given the target state (position, scale) of the initial frame (first frame) according to the tracked video sequence. The basic structure (framework) is as follows:
Basic process: input the initial frame and specify the target to be tracked, usually with a rectangular frame (Input Frame), generate many candidate frames (Motion Model) in the next frame and extract the features of these candidate frames (Feature Extractor), observation model ( Observation Model) to score these candidate boxes. Finally, find a candidate box with the highest score among these scores as the prediction target (Prediction A), or fuse multiple prediction values (Ensemble) to obtain a better prediction target. So far, the algorithm has completed the prediction of the second frame according to the information of the first frame, and so on for subsequent frames, while updating the model (Model Updater) according to the specified rules.
According to the above framework, target tracking is divided into five main research contents, as shown in the flowchart below:

Motion Model: How to generate numerous candidate samples.
Feature Extractor: What kind of features are used to represent the target.
Observe Model: How to score many candidate samples.
Model Updater: How to update the observed model to adapt to changes in the target.
Ensemble: How to fuse multiple decisions to get a better decision structure.
The summary of the figure below can help to better understand how the target tracking algorithm completes the tracking task.
2 Classification of target tracking algorithms
Most tracking methods mainly focus on the design of observation models, which can be divided into two categories according to different observation models: generative models and discriminative models.
Generative model: Build an appearance model by extracting target features, and then search the image for the region that best matches the model as a tracking result. Regardless of whether global features or local features are used, the essence of generative models is to find the closest candidate target to the target model as the current estimate in the high-dimensional space represented by the target. The disadvantage of such methods is that they only focus on the target information and ignore the background information, and it is prone to target drift or target loss when the target appearance changes drastically or is occluded.
Example: The tracker knows from the current frame that 80% of the target area is red and 20% is green. In the next frame, the search algorithm goes back to find the area that best matches this color ratio.
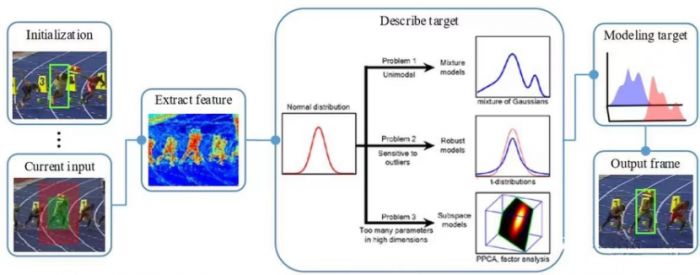
Discriminant method: regard target tracking as a binary classification problem, separate the target from the background by training a classifier about the target and the background, and determine the target from the candidate target, this method can significantly distinguish the background and the target, Robust performance, it has gradually become the mainstream method in the field of target tracking. And most of the current deep learning-based target tracking algorithms are also discriminative methods.
For example: tell the tracker during training that 80% of the target is red, 20% is green, and there is orange in the background. Pay special attention, so that the classifier knows more information and the effect is relatively good.
03 Difficulties and challenges of target tracking tasks
Although the application prospect of target tracking is very broad, there are still some problems that limit its application. The main problems are as follows:
Morphological Variation – Pose variation is a common disturbance problem in object tracking. When the pose of the moving target changes, its features and appearance model will change, which can easily lead to tracking failure. For example: athletes in sports competitions, pedestrians on the road.
Scale Variation – Scale adaptation is also a key issue in object tracking. When the target scale is reduced, since the tracking frame cannot be adaptively tracked, a lot of background information will be included, resulting in an error in the update of the target model: when the target scale is increased, since the tracking frame cannot completely include the target, the tracking frame Incomplete target information will also lead to errors in the update of the target model. Therefore, it is very necessary to realize scale adaptive tracking.
Occlusion and disappearance – The target may be occluded or disappear briefly during movement. When this happens, the tracking frame easily includes the occluder and background information in the tracking frame, which will cause the tracking target in subsequent frames to drift to the occluder. If the target is completely occluded, the tracking will fail because the corresponding model of the target cannot be found.
Image Blur – Changes in light intensity, fast moving objects, low resolution, etc. can cause object blur, especially if the moving object is similar to the background. Therefore, it is necessary to select effective features to distinguish the target from the background.
The diagrams below are some examples of the above problems.

As shown in the figure above, the difficulties and challenges in the target tracking task include:
1. Deformation, 2. Lighting change, 3. Similar interference, 4. Motion blur, 5. Background interference, 6. Occlusion, 7. Out of picture, 8. Scale change, 9. Out-of-plane propaganda, 10. In-plane rotation, 11. The background is similar
04 Target tracking database
Rigorous data sets are the key to driving the algorithm. In the past few years, the database resources in the direction of target tracking were relatively scarce, which is one of the important reasons why the development of target tracking lags behind target detection. Two authoritative databases of target tracking directions are briefly described below.
The VOT Challenge is a competition in the field of object tracking, similar to the ImageNet Challenge in the field of pattern recognition. These events are usually the source of standard datasets, so the VOT dataset is a commonly used target tracking dataset, and all sequences support free download. The VOT competition has been held for 9 sessions. Many new algorithms and unique ideas will appear in the competition every year. The VOT competition in 2022 will also be launched soon. Since the evaluation sequence will be updated every year, and the accuracy of the annotation will be improved year by year, the VOT competition will also be It is regarded as the hardest competition in the field of visual tracking, so the results are relatively more reliable.
The difference between OTB and VOT: OTB includes 25% grayscale sequence, while VOT is a color sequence, which is also the reason for the performance difference of many color feature algorithms. The evaluation indicators of the two libraries are different. For details, please refer to the paper and the official website of the competition.
5 Classical Target Tracking Algorithms
The most popular generative tracking method in the past few years is sparse coding (Sparse Coding), and recently the discriminative tracking method has gradually occupied the mainstream position, represented by correlation filter (CF: Correlation Filter) and deep learning (DL: Deep Learning) The discriminant method has achieved satisfactory results. This section briefly sorts out the classic algorithms in chronological order. The year of each algorithm is based on the year the paper was published or the year it participated in the benchmark to help understand the evolution and development trend of single-target tracking algorithms. The solution ideas proposed by each algorithm for the challenges of different tracking tasks are worth learning and experience, and the development trend of tracking algorithms is evident.
1981
LK Tracker 1981
LK Tracker should be the earliest target tracking work. It uses the concept of optical flow. As shown in the figure below, different colors indicate different directions of optical flow, and the depth of the color indicates the speed of movement. The calculation of optical flow is very simple and very fast, but its robustness is not good, and it can basically only track objects that are translated and their appearance is unchanged.

2002
Mean Shift
Mean Shift uses mean shift as the search strategy, which is a parameter-free probability estimation method. This method uses the image feature histogram to construct a spatially smooth probability density function, and searches for the local maximum value of the function by iterating along the gradient direction of the probability density function. . At that time, it became a commonly used target tracking method, which is simple and easy to implement, but has low robustness.
2010
MOSSE
MOSSE (Minimum Output Sum of Squared Error) uses correlation filtering for target tracking (not the first, but because of the clear thinking and the complete algorithm called the originator of the correlation filtering tracking algorithm), its speed can reach more than 600 frames per second, but The effect is mediocre, mainly because it only uses simple raw pixel features.
Rough process:
Re-enter the groundtruth of the initial frame (including the center point and the height and width of the rectangle)
Random affine transformation is performed on the current target frame to generate 128 samples, each sample is calculated by the Gaussian function to obtain the response value, and finally the filter template (FILTER in Figure 13) is obtained by combining the formula.
The response map of the second frame is calculated according to the template, and the point with the largest response value is the center point of the target of the second frame, and the target frame is drawn based on this (OUTPUT in Figure 13).
Update the filter template based on the target area of the second frame
Repeat steps 3-4
2012
CSK
The author of CSK has made some improvements for MOSSE. The author believes that the cyclic shift can simulate all the converted versions of the current positive sample (except the boundary), so the cyclic matrix is used for dense sampling (compared to the random affine sampling of MOSSE), and The low-dimensional linear space is mapped to the high-dimensional space by the kernel function, which improves the robustness of the correlation filter.
Circular matrix is a special kind of matrix. Its one-dimensional form is to move an n-dimensional vector to the right one element at a time, until an n×n matrix is generated. The specific effect is shown in the following figure.
2014
KCF
The feature input of CSK is single-channel grayscale pixels, while KCF uses HOG multi-channel features, and the kernel function uses a Gaussian kernel function.
It can be said that the combination of CSK and KCF is the evolution trend of the complete kernelized correlation filter. There are both cyclic matrix and Fourier diagonalization to simplify calculations, and the expansion of single-channel special applications, which can adapt to more excellent feature descriptions .
DSST
The DSST authors split the tracking into two parts – location changes and scale changes. During the tracking process, the author defines two filters to determine the location and scale evaluation of new targets respectively, which improves the robustness of the algorithm.
2015
MDNet
MDNet designs a lightweight small network to learn convolutional feature representation targets. The authors propose a multi-domain network framework.
During offline training, the feature extraction network is shared, and a new detection branch is constructed for each video sequence for training. In this way, the feature extraction network can learn more general domain-independent features.
During tracking, the feature extraction network is retained and fixed, a new branch detection part is constructed for the tracking sequence, and the detection part is trained online with the first frame samples, and then the tracking results are used to generate positive and negative samples to fine-tune the detection branch.
In addition, MDNet uses the difficult example mining technology to generate negative samples during training. As the training progresses, the classification difficulty of the samples increases, which makes the network’s discriminative ability stronger and stronger.
As shown in the figure below, the negative samples are getting harder and harder to separate.
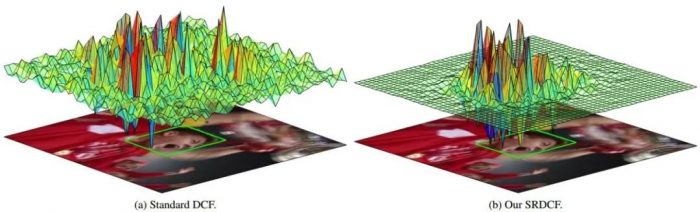
SRDCF
The authors of SRDCF considered that if only simple correlation filtering is used, it will lead to boundary effects, that is, correlation filtering uses cyclic shift sampling, which will cause the target to be divided when it is shifted to the edge. At this time, there is no complete target in the obtained sample. The image thus loses its effect.
Therefore, the author’s idea is that since the boundary effect occurs near the boundary, then ignore the boundary part pixels of all shifted samples, or restrict the filter coefficient near the boundary to be close to 0. The specific method is to add spatial regularization to penalize the boundary area. Filter coefficients, the effect is as shown below.
HCF
The main contribution of HCF is to replace the HOG feature in the correlation filter with the depth feature. It uses three layers of VGG, 3, 4, and 5 to extract features, train a filter for each layer of CNN, and follow the steps from deep to deep. The shallow order uses correlation filtering, and then uses the results from the deep layers to guide the shallow layers to reduce the search space.
The above picture is obtained using convolution visualization. As shown in the figure, the features in conv3 can clearly see the outline of the target, but it is difficult to see the details in conv5, but it can be seen in conv5 The feature of this layer contains a lot of semantic information, and the highlighted area in the left half is the approximate area where the target is located, so in the high-level features, it is easy to find the approximate area where the target is located, and then Gradually use lower-level features for precise localization of objects.
2016
Staple
Staple proposes a complementary approach. Considering that the HOG feature is more sensitive to deformation and motion blur, but can achieve a good tracking effect on color changes, the color feature is more sensitive to color, but can have a good tracking effect on deformation and motion blur, so the author believes that if it can Complementing the two can solve some of the main problems encountered in the tracking process. Therefore, Staple uses the HOG-KCF and color-KCF combination algorithm to track the target.
The innovative idea of this algorithm is simple and straightforward, but the effect is amazing.
TCNN
TCNN uses a tree-like structure to process CNN features. The author uses reliability to assign the weight of the predicted target. The update strategy adopted is to delete the front node every 10 frames, and create a new CNN node at the same time, and select the node that can make the new node with the highest reliability as its parent node. In this way, an active set is always maintained, which contains 10 newly updated CNN models, and this active set is used for tracking. However, the speed is slower due to the need to update the network structure.
siamFC
The core idea of the SiamFC method is very simple, which is to formulate the tracking process as a similarity learning problem. That is, learn a function f(z, x) to compare the similarity between the sample image z and the search image x, and if the two images are more similar, the higher the score. In order to find the position of the target in the next frame of image, we can test all possible positions of the target, and use the position with the greatest similarity as the predicted position of the target.
2017
CFNet
CFNet adopts the architecture of the twin network, the training samples (here refers to the template used for matching) and the test samples (the searched image area) pass through the same network, and then only the training samples are subjected to relevant filtering operations to form a robust to changes. sex template. To suppress boundary effects, the authors imposed a cosine window and then cropped the training samples.
2018
UPDT
The main idea of the UPDT algorithm is to treat deep features and shallow features differently. Deep features can improve the effect through data enhancement. At the same time, the main feature of deep features is robustness rather than accuracy; on the contrary, shallow features are reduced by data enhancement. effect, but at the same time it can guarantee the accuracy well. Therefore, the author has come up with a scheme in which the deep model and the shallow model are trained independently first and then merged at the end.
SiamRPN
SiamRPN utilizes the RPN in Faster RCNN on the basis of SiamFC, which solves the problem that the previous deep learning tracking algorithm does not have domain specific (understandable as indistinguishable between classes) and requires additional scale detection and online fine-tuning. The introduction of the RPN regression network, on the one hand, improves the accuracy, and on the other hand, the regression process replaces multi-scale detection, which improves the speed.
2019
SiamRCNN
SiamRCNN found that re-detection is easily affected by distractors, resulting in model drift. Starting from the perspectives of difficult case mining and motion trajectory dynamic planning, a twin network detection structure using the first frame and the previous frame as templates was designed. The effect of short-term tracking evaluation is amazing, and there is also a very significant improvement in long-term tracking evaluation.
The main idea of Trajectory Dynamic Programming (TDPA) is to re-detect all target candidate boxes in the previous frame and group these candidate boxes into short target trajectories over time, while tracking all potential targets, including interfering targets. The current best object is then selected based on the complete historical trajectories of all target objects and interfering objects in the video.
2020
RPT framework
The RPT algorithm framework consists of two parts: the target state estimation network and the online classification network:
The target state estimation network expresses the tracking target state as a feature point set to improve the modeling ability of target pose changes and geometric structure changes. In the visual target tracking task, in order to facilitate ground truth labeling and feature extraction, the target state is usually represented by a rectangular frame. On the one hand, the rectangular box is a rough representation of the target area and contains redundant background; on the other hand, it does not have the ability to model the changes of the target pose and geometric structure, which limits the regression accuracy. Therefore, the tracking target is represented as a series of feature points, and the semantic key points and extreme points in the target area are supervised and learned to achieve a more refined target state estimation.
07 References related to learning target tracking
a) Getting Started
I believe this article can help you understand “what is goal tracking” and “what kind of thing goal tracking is to accomplish”. The following article introduces each sub-problem in the target tracking task process in more detail (refer to the flowchart in the first section of this article).
In addition, if you want to get started with target tracking (also applicable to other tasks in computer vision, such as target detection, etc.), you can start with learning OpenCV, first master basic image processing, and extract image features to effectively describe the target. Recommend a simple and easy-to-use OpenCV introductory course
b) Advanced
It is recommended that you study a classic target tracking algorithm in depth. Since there are many detailed principles of the specific algorithm, I will not repeat them here. Here are several classic tracking algorithm learning materials, and you can also choose one or two other classic algorithms. For in-depth study:
First, we recommend a Tracking Benchmark for Correlation Filters maintained on github, which summarizes the target tracking algorithms of correlation filtering and classifies them according to the problems solved by each paper: https://github.com/HEscop/TBCF


GIPHY App Key not set. Please check settings